News & Announcements

BMIR Division and Research News
Announcing the Launch of the RADx Tribal Data Repository | Data Science at NIH
To address the disparities recognized in these communities, the NIH has focused on supporting research projects that can increase our overall understanding of COVID-19 and its effects on American Indian and Alaska Native communities. This week, NIH Office of Data Science Strategy announced the launch of the RADx Tribal Data Repository: Data for Indigenous Implementations, Interventions, and Innovations (RADx TDR: D4I).
Director’s Message: RADx Tribal Data Repository
RADx TDR establishes a data repository for responsible data access and sharing of RADx American Indian and Alaska Native research data. NIH establishes the RADx Tribal Data Repository (TDR)! This novel initiative will focus on responsible data sharing among researchers working with American Indian and Alaska Native communities.
Artificial Intelligence (AI) Research and Opinion Articles from JAMA Network
Explore clinical applications of AI in the JAMA Network, including research and opinion about the use of deep learning and neural networks for clinical image analysis, natural language processing, EHR data mining, and more
News
Awards for Supporting Actors: The Benefits of Being a Team Player
As research is more and more conducted in teams, what are the benefits of playing a supporting role? Five faculty share their perspectives on the benefits of team science.
Trends in Influenza Vaccination Rates among a Medicaid Population from 2016 to 2021
Seasonal influenza is a leading cause of death in the U.S., causing significant morbidity, mortality, and economic burden. Despite the proven efficacy of vaccinations, rates remain notably low, especially among Medicaid enrollees. Leveraging Medicaid claims data, this study characterizes influenza vaccination rates among Medicaid enrollees and aims to elucidate factors influencing vaccine uptake, providing insights that might also be applicable to other vaccine-preventable diseases, including COVID-19. This study used Medicaid claims data from nine U.S. states (2016–2021], encompassing three types of claims: fee-for-service, major Medicaid managed care plan, and combined. We included Medicaid enrollees who had an in-person healthcare encounter during an influenza season in this period, excluding those under 6 months of age, over 65 years, or having telehealth-only encounters. Vaccination was the primary outcome, with secondary outcomes involving in-person healthcare encounters. Chi-square tests, multivariable logistic regression, and Fisher’s exact test were utilized for statistical analysis. A total of 20,868,910 enrollees with at least one healthcare encounter in at least one influenza season were included in the study population between 2016 and 2021. Overall, 15% (N = 3,050,471) of enrollees received an influenza vaccine between 2016 and 2021. During peri-COVID periods, there was an increase in vaccination rates among enrollees compared to pre-COVID periods, from 14% to 16%. Children had the highest influenza vaccination rates among all age groups at 29%, whereas only 17% were of 5–17 years, and 10% were of the 18–64 years were vaccinated. We observed differences in the likelihood of receiving the influenza vaccine among enrollees based on their health conditions and medical encounters. In a study of Medicaid enrollees across nine states, 15% received an influenza vaccine from July 2016 to June 2021. Vaccination rates rose annually, peaking during peri-COVID seasons. The highest uptake was among children (6 months–4 years), and the lowest was in adults (18–64 years). Female gender, urban residency, and Medicaid-managed care affiliation positively influenced uptake. However, mental health and substance abuse disorders decreased the likelihood. This study, reliant on Medicaid claims data, underscores the need for outreach services.
A surprising revelation about ChatGPT’s contribution
ChatGPT’s responses to queries about handling a difficult doctor-patient conversation shows one physician what we can learn from such tools.
A Better Way to Predict Complex Genotypes with Limited Data
Learn how we are healing patients through science & compassion
Multi-omics analysis of mucosal and systemic immunity to SARS-CoV-2 after birth
Multi-omics analysis of blood and nasal samples from human infants and their mothers indicates strong and sustained immunity following SARS-CoV-2 infection during the initial months of life.
Leaders discuss AI, equity, aging and cancer at first Big Ideas in Medicine conference
Physicians, researchers and other pacesetters describe some of the most promising pursuits in the medical field. In cancer, for instance: ‘Let’s kill the first cell, not the last cell.’
Whole Slide Imaging-Based Prediction of TP53 Mutations Identifies an Aggressive Disease Phenotype in Prostate Cancer
Deep learning models predicting TP53 mutations from whole slide images of prostate cancer capture histologic phenotypes associated with stromal composition, lymph node metastasis, and biochemical recurrence, indicating their potential as in silico prognostic biomarkers.
News

Treating COVID-19 Patients: What We Can Learn
Physician-scientists Jonathan Chen, MD, PhD, and Lance Downing, MD, have taken care of over 50 COVID patients in the hospital and in clinic since the beginning of the pandemic. They were asked how their experience in treating those patients relates to BMIR’s mission in informatics.
Announcement

Dr. Tina Hernandez-Boussard awarded R01 from AHRQ
Her research proposal titled “Identifying Optimal Pain Management for Elders” was awarded this month. Hernandez-Boussard and her team of researchers will build an innovative approach to advance the systematic analysis of postoperative pain in elders to improve pain management and patient outcomes.
This project will deliver validated risk-stratification tools derived from real world evidence to identify elder patients at high risk for adverse pain outcomes following surgery.
News
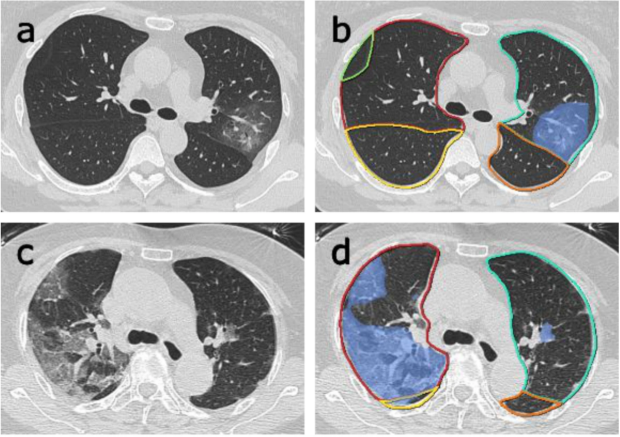
BMIR’s Assistant Professor Olivier Gevaert’s paper published in Nature – Partner Journals
Dr. Gevaert’s paper was published on the power of AI analysis of CT images for rapid triage of COVID 19 patients.
Great work by students & trainees in the Gevaert lab on developing an AI-based approach combining clinical, lab data and CT imaging to triage COVID-19 patients: Qinmei "May" Xu, Xianghao(Sam) Zhan, Yiheng "Terry" Li and Peiyi "Penny" Xie.
News
Dr. Nigam Shah’s on Stanford COVID-19 patients highlighted in NBC Bay Area news
BMIR faculty member Dr. Nigam Shah’s Green Button Project is discussed in an NBC Bay Area News segment. Shah’s Informatics Consult Service is positioned to help healthcare providers fight COVID-19 hospitalization and pinpoint who is at greater risk of serious illness.
BMIR's Newsletter
Connection

See the latest happening with BMIR and CONNECT with us.